


NVIDIA ChatRTX lokálny - AI model ktorý sa učí na vašich dokumentoch
NVIDIA ChatRTX je vzorová aplikácia, ktorá vám umožňuje prepojiť LLM (Large Language Model) s vaším vlastným obsahom – dokumentmi, poznámkami, fotografiami alebo inými údajmi. Využíva RAG (Retrieval-Augmented Generation) a TensorRT-LLM. ChatRTX momentálne podporuje GPU série RTX 3xxx a RTX 4xxx, ktoré majú aspoň 8 GB pamäte GPU
ChatRTX testujem na hernom notebooku Gigabyte s grafikou NVIDIA GeForce RTX 4060, ktorá má 8 GB VRAM. Úmyselne som vybral takúto zostavu, aby som ukázal možnosti behu lokálnych AI jazykových modeloch na cenovo dostupných grafických kartách. Potrebujete minimálne 100 GB voľného miesta na disku.
Námetom prvého videa je predstavenie Chat RTX, postup inštalácie, ukážky odpovedí využívajúce lokálny AI jazykový model Mistral-7B a ukážka trénovania na adresári s textami
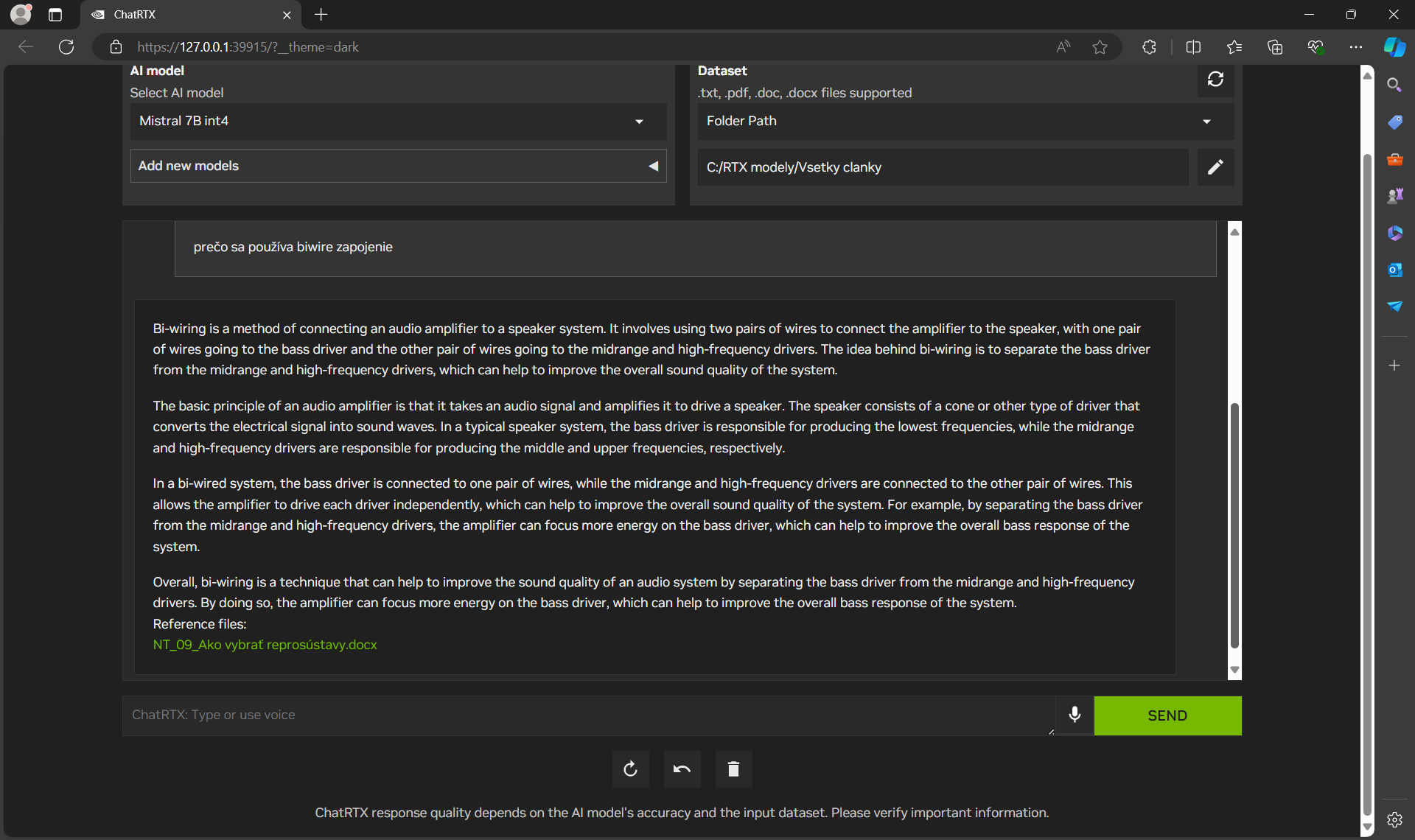
V druhom videu je ukážka fungovania ChatRTX, ktorý bol natrénovaný na mojom archíve článkov, ktoré som napísal za posledných 10 rokov. Dôležitá informácia je, že všetky články v adresároch použité na trénovanie jazykového modelu boli. v slovenčine.
Inštalačný súbor má takmer 12 GB, pretože obsahuje aj lokálny AI jazykový model Mistral-7B. Následná inštalácia je jednoduchá. Napriek tomu, že NVIDIA Chat RTX beží na lokálnom počítači, je to aplikácia klient server, pričom aplikácia obsahujúca klientske rozhranie a aj serverová časť beží na vašom počítači. Pri spúšťaní serverovej časti sa zobrazí okno konzolovej aplikácie, v ktorom vidíte priebeh fungovania, prípadne trénovania modelu na vašich dokumentoch. Implicitne je pre lokálne trénovanie modelu nastavený adresár s dokumentami obsahujúci texty z blogov NVIDIA. Sú uložené v súboroch s príponou .TXT. Po nábehu aplikácie približne 1 – 2 minúty prebieha dotrénovanie modelu na týchto súboroch, takže s aplikáciou nie je možné pracovať. Aplikácia používa techniku nazývanú Retrieval Augmented Generation (RAG) na vyhľadanie miestnych súborov, na ktoré odkazujete, a tieto informácie použije na poskytnutie kontextu, keď odošle vašu otázku LLM.
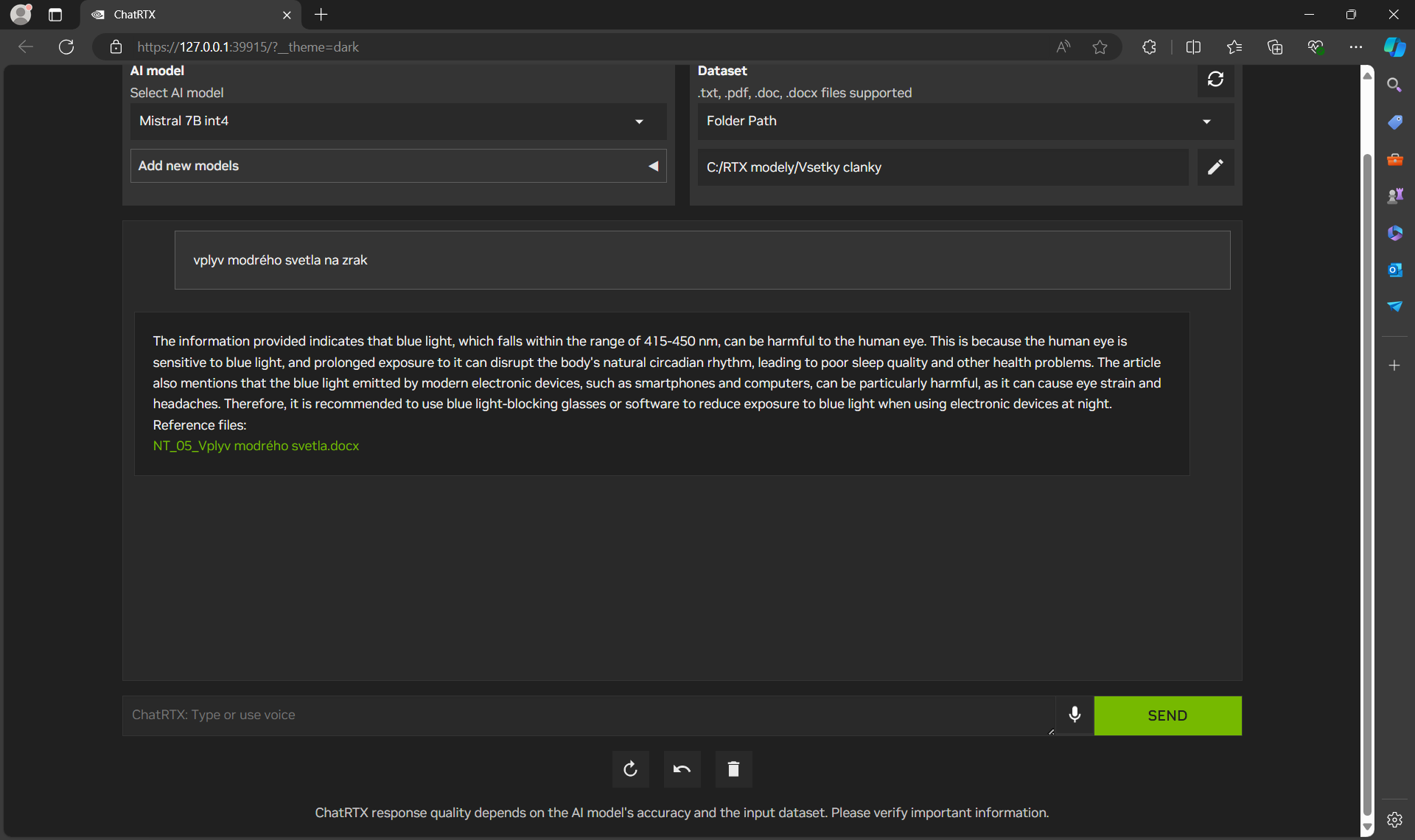
Po natrénovaní na týchto informáciách z blogu NVIDIA sa môžete buď prepnúť na natrénovaný, lokálne nainštalovaný a bežiaci jazykový model Mistral-7B, alebo inicializovať trénovanie na vašich dokumentoch. ChatRTX podporuje rôzne formáty súborov vrátane textu, pdf, doc/docx a obrázky vo formáte jpeg, gif a png. Ja som model trénoval na mojom archíve článkov, ktoré som napísal za posledných 10 rokov. Priečinok s článkami obsahoval 2 168 súborov, konkrétne dokumentov programu Word vo formáte docx. Súbory zaberali 160 MB. Trénovanie na notebooku s GPU NVIDIA RTX 4060 s 8 GB VRAM trvalo 27 minút
Samozrejme pri použití modelu natrénovaného na vašich dokumentoch má zmysel dávať len otázky, alebo zadania týkajúce sa informácii ktoré model získal z dokumentov na ktorých sa trénoval. Po natrénovaní som preto položil otázku: Ako efektívne využiť fotovoltiku na ohrev teplej úžitkovej vody? Otázku som napísal v slovenčine. Odpoveď som dostal v angličtine, predsa len je to lokálny jazykový model a nemôžeme od neho chcieť aby dokázal to, čo dokážu veľké LLM modely bežiace v cloude. Súčasťou odpovede bol aj link na článok uložený v lokálnom adresári na notebooku. Pre zaujímavosť odpoveď som si nechal strojovo preložiť a porovnal som ju s informáciami v článku. Odpoveď bola viac menej relevantná, akurát AI model nevedel dosť dobre rozlíšiť medzi bojlerom s dvomi špirálami a kaskádou dvoch bojlerov.
Ak ste prepnutí na model natrénovaný na vašich dokumentoch a položíte otázku, alebo zadanie ku ktorému v dokumentoch nie sú informácie. Odpoveď nezískate. Píšem len technologické články, nemám žiadny cestovateľský blog, takže na zadanie: Potrebujem odporučiť zaujímavé miesta, ktoré sa vyplatí navštíviť v Barcelone som odpoveď nedostal. Po prepnutí na model Mistral-7B natrénovaný na všeobecných informáciách z internetu som dostal relevantné tipy na 12 zaujímavých miest, ktoré sa v Barcelone oplatí navštíviť.
Technologické demo ChatRTX je vytvorené z referenčného projektu vývojára TensorRT-LLM RAG dostupného na GitHue. Vývojári môžu použiť tento odkaz na vývoj a nasadenie svojich vlastných aplikácií založených na RAG pre RTX, zrýchlené pomocou TensorRT-LLM.
Môžete si vybrať ďalšie modely kompatibilné s TensorRT-LLM, ktoré máte nainštalované (napr. Llama 2-7B int4) kliknutím na políčko výberu označené ako „Vybrať model AI“
Aplikácia používa techniku nazývanú Retrieval Augmented Generation (RAG) na vyhľadanie miestnych súborov, na ktoré odkazujete, a tieto informácie použije na poskytnutie kontextu, keď odošle vašu otázku LLM. Deaktivácia RAG bude mať za následok, že LLM bude generovať odpovede výlučne na základe údajov, s ktorými bol pôvodne trénovaný. Aby ste videli, ako by LLM reagoval bez RAG, môžete RAG deaktivovať výberom „AI Model Default“ z rozbaľovacej ponuky vpravo (pozri obrázok nižšie).
Okrem predinštalovaného modelu Mistral LLM si môžete stiahnuť a nainštalovať model CLIP na prácu s obrázkami Po nainštalovaní modelu môžete aplikáciu nasmerovať do priečinka obrázkov jpeg a pýtať sa na zobrazovaný obsah . Napríklad „Ukáž mi obrázky, na ktorých sú psy“, „Ktoré obrázky boli nasnímané v miestnosti“ a podobne. Obrázkom budeme venovať ďalší článok.
ChatRTX má integrovaný Whisper, ktorý vykonáva transformáciu reči na text, takže otázky, prípadne zadania môžete nielen písať, ale aj diktovať do mikrofónu. Podporované sú zatiaľ majoritné svetové jazyky.
Údaje, ktoré ChatRTX načíta do vektorovej knižnice, sú fragmentované, čiže rozdelené na úseky určitej dĺžky. Z týchto fragmentov sa potom generujú odpovede. Z toho vyplýva že ChatRTX dokáže extrahovať informácie, ale nedokáže zosumarizovať celý dokument. Aplikácia si nepamätá kontext. To znamená, že doplňujúce otázky nebudú zodpovedané na základe kontextu predchádzajúcich otázok.
Vhodný notebook s GPU NVIDIA Geforce RTX 40xx si môžete vybrať na Smarty.sk
Zobrazit Galériu
