



LLM už môžete trénovať aj na staršom “železe”
Nedávno výskumníci z čínskej Soochow University vydali výskumnú prácu s názvom MemLong: Memory-Augmented Retrieval for Long Text Modeling, v ktorej úspešne rozšírili kontextové okno LLM z 2k na 80k tokenov na dvojročnom grafickom procesore NVIDIA 3090. To otvára nové obzory pre používateľov s obmedzeným prístupom k hardvéru, ktorí napriek tomu chcú používať aplikácie s AI lokálne na svojich počítačoch.
Ďalším vrcholom tejto štúdie bolo doladenie verzie MemLong s 3 miliardami parametrov na 0,5 miliardy tokenov, ktoré si vyžaduje iba osem GPU 3090 počas ôsmich hodín, čo demonštruje vysokú efektivitu využívania zdrojov. To prináša úžitok nielen pre používateľov, ktorí chcú spúšťať aplikácie AI, ale aj pre vývojárov, ktorí chcú trénovať svoje modely na hardvéri strednej triedy. Metóda bola navrhnutá s cieľom rozšíriť možnosti modelovania jazyka s dlhým kontextom využitím externého vyhľadávača na vyhľadávanie historických informácií.

Kľúčovou myšlienkou je ukladať minulé kontexty a znalosti do netrénovateľnej pamäťovej banky. Tento prístup využíva pamäťovú banku na ukladanie minulých kontextov a znalostí, ktoré sa počas tréningu nemenia, a zabezpečuje, že uložené informácie zostanú v priebehu času konzistentné. Zmrazením spodných vrstiev modelu a dolaďovaním iba horných vrstiev MemLong znižuje výpočtové náklady. Tento prístup umožňuje efektívny tréning vyžadujúci menej zdrojov pri zachovaní vysokého výkonu.
Modely hlbokého učenia, ktoré dosahujú pôsobivé výsledky v porovnávacích testoch, môžu vykazovať prekvapivo slabý výkon v reálnom svete, zvyčajne v dôsledku distribučných posunov. Riešenie distribučných posunov je obrovský problém a modely deep learning sa často môžu naučiť falošné korelácie. To vysvetľuje, prečo je dôležité mať konzistentné informácie distribuované v rôznych kontextoch.
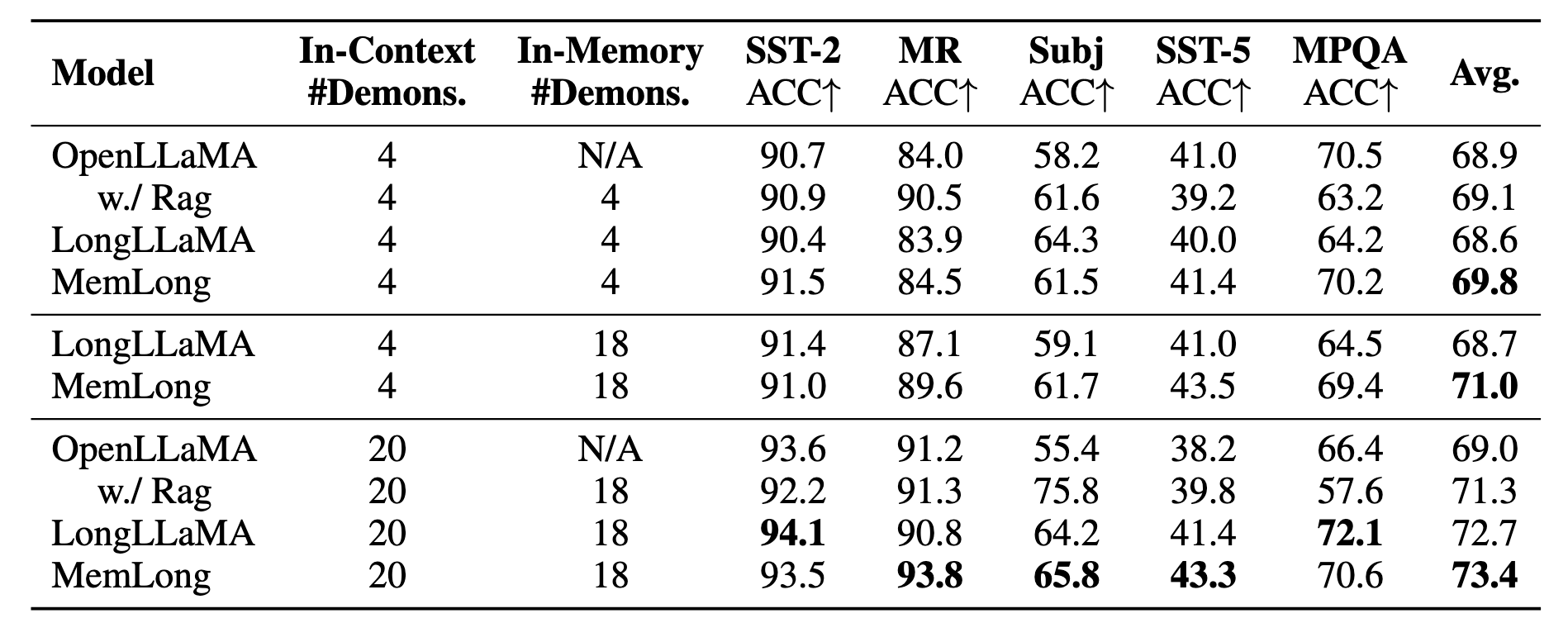
MemLong prekonáva najmodernejšie modely v úlohách s dlhým kontextom a dosahuje zlepšenie až o 10,2 percentuálneho bodu v porovnaní s modelmi ako OpenLLaMA v úlohách kontextového učenia s rozšíreným vyhľadávaním. Ďalšou kľúčovou časťou tohto výskumu je fungovanie na sémantickej úrovni relevantných dávok informácií, čo umožňuje koherentnejšie modelovanie dlhého textu.

Spracovaním textu na úrovni blokov môže MemLong zachovať sémantickú koherenciu v dlhých sekvenciách, čo je nevyhnutné pri úlohách, ako je sumarizácia dokumentov a dialógové systémy. MemLong namiesto priameho spracovania veľkých textových vstupov používa mechanizmus načítania historických informácií ako dvojice kľúč – hodnota.
Zdroj: analyticsindiamag.com.
Zdroj Foto: freepik.com.
Zobrazit Galériu

