ML a neurónové siete v praktických príkladoch / IV. Programujeme model neurónovej siete
Námetom tejto časti je naprogramovanie modelu neurónovej siete v Pythone pomocou funkcií knižnice PyTorch.
Aby ste mohli vyskúšať prezentované príklady, budete potrebovať knižnicu PyTorch, ktorá umožňuje spracúvať dáta a písať algoritmy strojového učenia v programovacom jazyku Python, a interaktívne prostredie Jupyter Notebook. Môžete si toto prostredie nainštalovať, návody pre Windows aj Ubuntu Linux nájdete na našom kanáli YouTube, prípadne môžete pracovať v online prostredí Google Colaboratory (Colab) https://colab.research.google.com. To umožňuje vytvárať a spúšťať kód v programovacom jazyku Python priamo v prehliadači bez toho, aby ste čokoľvek museli inštalovať na svoj počítač. Colaboratory je cloudová implementácia nástroja Jupyter Notebook, ktorá beží na virtuálnych serveroch Googlu a môže využívať na výpočty aj GPU a technológiu NVIDIA CUDA. Inak povedané, môžete využívať mnohonásobné urýchlenie náročných výpočtov pomocou GPU aj v prípade, ak vo svojom počítači nemáte grafickú kartu. Kompletné príklady aj s výpismi nájdete na GitHube v repozitári https://github.com/lubolacko/ML-v-Pythone-priklady, odkiaľ si ich môžete spustiť priamo v prostredí Google Colab.
Procesný postup strojového učenia v PyTorch pozostáva z niekoľkých na seba nadväzujúcich krokov:
- Príprava údajov – načítame množinu údajov, prípadne ich upravíme, vyčistíme a zjednotíme. Následne údaje rozdelíme na tréningovú a testovaciu množinu. Napríklad 80 % údajov využijeme na trénovanie a 20 % na testovanie.
- Programovanie modelu neurónovej siete na objavenie vzorov v dátach – samozrejme, podarí sa to iba vtedy, ak v údajoch nejaké existujú.
- Zvolíme stratovú funkciu, optimalizátor a naprogramujeme tréningovú slučku.
- Trénovanie modelu – necháme model skúsiť nájsť vzory v tréningových dátach.
- V etape vyhodnotenia modelu porovnáme vzory nájdené modelom so skutočnými testovacími údajmi.
- Ak model vyhovuje, použijeme ho na predpovedanie, napríklad na generovanie textu či rozpoznávanie obrázkov.
Úvodný príklad
Vytvoríme veľmi jednoduchý príklad, v ktorom umelo vygenerujeme údaje podľa vzťahu y = weight * X + bias, pričom parametre weight a bias zadáme. Model tieto parametre nepozná. Budeme generovať priamo tenzory. Rozdelíme údaje na tréningovú a testovaciu množinu.
import torch from torch import nn import matplotlib.pyplot as plt weight, bias = 0.8, 0.4 start, end, step = 0, 1, 0.01 X = torch.arange(start, end, step).unsqueeze(dim=1) #vstupy y = weight * X + bias #výstupy #rozdelenie na tréningovú a testovaciu množinu train_split = int(0.8 * len(X)) # 80% tréningové, 20% testovacie X_train, y_train = X[:train_split], y[:train_split] #tréningové X_test, y_test = X[train_split:], y[train_split:] #testovacie #Počet údajov v množinách len(X_train), len(y_train), len(X_test), len(y_test) ---výpis--- (80, 80, 20, 20)Kód triedy modelu využívajúceho lineárnu regresiu. Vytvoríme inštanciu modelu s našou triedou a skontrolujeme jej parametre.
class Model(nn.Module): # trieda odvodená od nn.Module def __init__(self): # konštruktor super().__init__() # voláme konštruktor rodičovskej triedy # na spresnenie váhových koeficientov a bias použijeme gradient descent self.weights = nn.Parameter(torch.randn(1, dtype=torch.float), requires_grad=True) # začíname náhodnými váhovými koeficientmi self.bias = nn.Parameter(torch.randn(1, dtype=torch.float), requires_grad=True) # začíname náhodnými biasmi # dopredný prechod pri predpovedaní def forward(self, x: torch.Tensor) -> torch.Tensor: # x - vstupy # výpočet lineárnej regresie (y = a*x + b) return self.weights * x + self.bias torch.manual_seed(42) #náhodné model = Model() model.state_dict() #weights a bias zatiaľ náhodnéModel zatiaľ neberie do úvahy hodnoty z tréningovej množiny, predpovede robí pomocou náhodných parametrov na výpočty, ľudovo povedané, len háda.
Aby sme to napravili, treba aktualizovať jeho interné parametre váhy a hodnoty odchýlky, ktoré sme pri inicializácii nastavili náhodne. My tie parametre poznáme (weight = 0.8 a bias = 0.4), ale model nie. V procese tréningu by to mal zistiť. Aby si náš model sám aktualizoval parametre, potrebujeme pridať stratovú funkciu a optimalizátor.
Vytvorenie stratovej funkcie a optimalizátora
PyTorch má implementovaných veľa stratových funkcií. Pre našu úlohu vyberieme stratovú funkciu (MAE Mean absolute error) torch.nn.L1Loss()), ktorá meria absolútny rozdiel medzi dvoma bodmi – predpoveďami a výsledkami – a potom berie priemer zo všetkých príkladov.
Optimalizátor „povie“ vášmu modelu, ako aktualizovať jeho interné parametre, aby sa čo najviac znížila strata. PyTorch má rôzne implementácie optimalizačných funkcií. Napríklad Stochastic gradient descent (torch.optim.SGD()) alebo Adam optimizer (torch.optim.Adam()). Zvolíme SGD.
Budeme optimalizovať hodnoty váh a odchýlky, ktoré sme predtým nastavili náhodne. Parameter lr je rýchlosť učenia, pri ktorej má optimalizátor aktualizovať parametre, vyššia hodnota znamená, že optimalizátor sa pokúsi o väčšie aktualizácie. Typická počiatočná hodnota pre rýchlosť učenia je 0,01.
loss_fn = nn.L1Loss() # MAE loss optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01) # parametre, ktoré sa budú optimalizovaťVytvorenie tréningovej optimalizačnej slučky
Model sa učí vzťahy medzi parametrami a výsledkami. Slučka prechádza testovacími údajmi a vyhodnocuje, aké dobré sú vzory, ktoré sa model naučil na tréningových údajoch. V slučke potrebujeme, aby model prezrel každú vzorku v súbore údajov.
Slučka obsahuje tieto kroky:
- Dopredný prechod – model prejde všetkými tréningovými údajmi a vykoná výpočty funkcie forward(). Volá sa funkcia model(x_train).
- Výpočet straty – výstupy modelu, teda predpovede sa porovnajú s výsledkami, aby sa zistilo, ako sa predpovede líšia od pravdy, a vyhodnotia sa, aby sa zistilo, nakoľko sú nesprávne. Volá sa funkcia loss = loss_fn(y_pred, y_train).
- Nulové gradienty – gradienty optimalizátorov sú nastavené na nulu, takže ich možno prepočítať pre konkrétny tréningový krok. Volá sa funkcia optimalizátor.zero_grad().
- Backpropagation čiže spätné šírenie pri strate. Vypočíta sa gradient straty vzhľadom na každý parameter modelu, ktorý sa má aktualizovať (pre každý parameter s require_grad=True). Volá sa loss.backward().
- Aktualizácia optimalizátora (gradient descent čiže klesanie gradientu) – aktualizujú sa parametre s require_grad=True s ohľadom na gradienty strát, aby sa zlepšili. Volá sa optimizer.step().
Testovacia slučka neobsahuje vykonávanie spätného šírenia (loss.backward()) ani krokovanie optimalizátora (optimizer.step()), pretože počas testovania sa nemenia žiadne parametre v modeli, tie už boli vypočítané počas tréningu. Pri testovaní nás zaujíma iba výstup z priameho prechodu cez model.
torch.manual_seed(42) epochs = 200 # počet iterácií - koľkokrát model prechádza tréningové dáta # prázdne zoznamy train_loss_values = [] test_loss_values = [] epoch_count = [] # tréning # ------- for epoch in range(epochs): model.train() y_pred = model(X_train) # forward pass, volá sa metóda forward() loss = loss_fn(y_pred, y_train) optimizer.zero_grad() #nulové gradienty loss.backward() optimizer.step() # optimsalizácia parametrov # testovanie # ---------- model.eval() #model v evaluation mode with torch.inference_mode(): test_pred = model(X_test) # forward pass cez testovacie dáta test_loss = loss_fn(test_pred, y_test.type(torch.float)) # výpis ako to prebieha, každých 10 iterácii if epoch % 10 == 0: epoch_count.append(epoch) train_loss_values.append(loss.detach().numpy()) test_loss_values.append(test_loss.detach().numpy()) print(f"Iterácia: {epoch} | Train Loss: {loss} | Test Loss: {test_loss} ") ---výpis--- Iterácia: 0 | Train Loss: 0.4541979432106018 | Test Loss: 0.6723175048828125 Iterácia: 10 | Train Loss: 0.33859533071517944 | Test Loss: 0.536965012550354 ... Iterácia: 190 | Train Loss: 0.0076020522974431515 | Test Loss: 0.017007315531373024
Môžeme vykresliť graf tréningovej a testovacej krivky.
plt.plot(epoch_count, train_loss_values, label="Train loss") plt.plot(epoch_count, test_loss_values, label="Test loss") plt.ylabel("Loss") plt.xlabel("Epochs") plt.legend();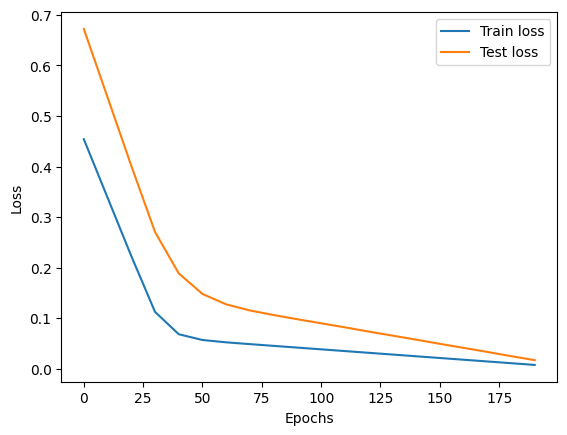
Stratové krivky ukazujú, že strata postupne klesá. Strata je mierkou toho, aký nesprávny je váš model, takže čím nižšia, tým lepšia. Strata klesla preto, lebo vďaka stratovej funkcii a optimalizátoru boli aktualizované interné parametre modelu (váhy a odchýlky), aby lepšie odrážali vzory v údajoch.
Metóda .state_dict() udáva, ako sa model približuje ku skutočným hodnotám.
print(model.state_dict()) ---výpis--- OrderedDict([('weights', tensor([0.7792])), ('bias', tensor([0.4088]))])
Originálne hodnoty sú: weights= 0.8 bias= 0.4
Model sa priblížil k originálnym hodnotám a pravdepodobne by sa ešte viac priblížil, keby sme ho trénovali dlhšie, cez viac iterácií, napríklad 1000. Pravdepodobne by ich neuhádol presne, ale to nič, väčšinou stačí čo najbližšia aproximácia.
Generovanie predpovedí
Model treba nastaviť do hodnotiaceho režimu model.eval(). Predpovede sa generujú pomocou kontextového manažéra v inferenčnom móde.
model.eval() with torch.inference_mode(): y_predp = model(X_test) y_predp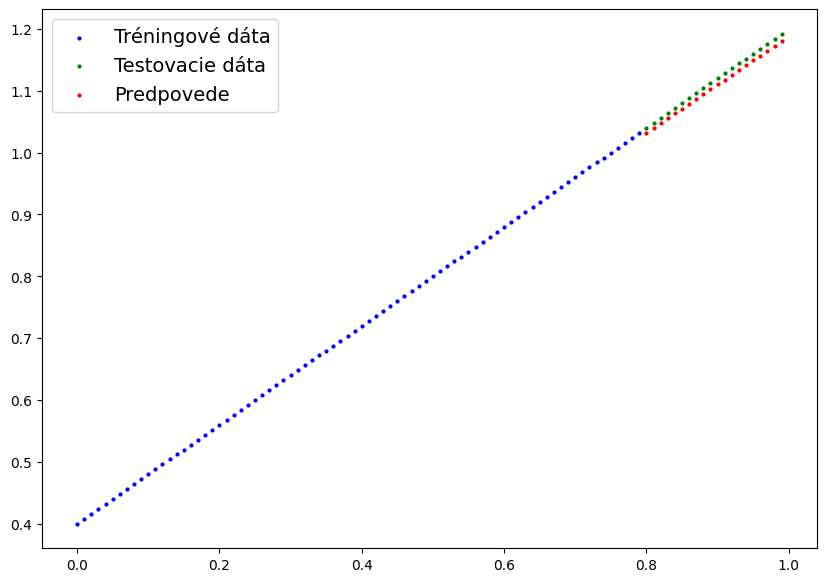
Na lepšiu názornosť vytvoríme funkciu na grafickú vizualizáciu údajov.
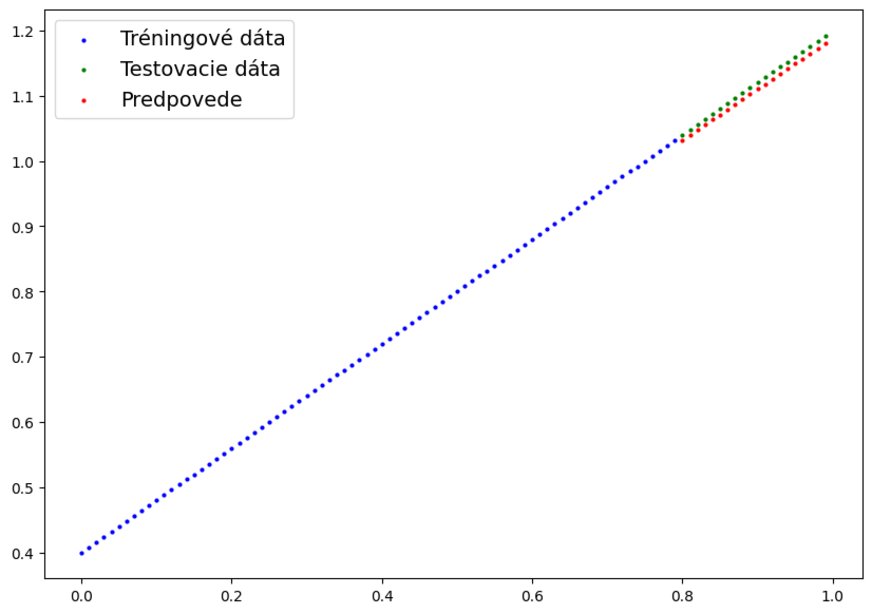
def graf_predpovedi(train_data=X_train,train_labels=y_train, test_data=X_test, test_labels=y_test, predpovede=None): plt.figure(figsize=(10, 7)) plt.scatter(train_data, train_labels, c="b", s=4, label="Tréningové dáta") #modrá plt.scatter(test_data, test_labels, c="g", s=4, label="Testovacie dáta") #zelená if predpovede is not None: plt.scatter(test_data, predpovede, c="r", s=4, label="Predpovede") #červené plt.legend(prop={"size": 14}); [ ] graf_predpovedi(predpovede=y_predp)
V grafe názorne vidíte odchýlku predpovedí od reálnych hodnôt.
V budúcom pokračovaní ukážeme reálny príklad neurónovej siete, ktorá predpovedá výskyt cukrovky.
Zobrazit Galériu